This project was made by Dušan and me as part of the Petnica ML seminar (check it out here), as our final project for the seminar.
Previously for the DSTL Kaggle competition, we’ve used a U-net architecture. So we used it here again, and it turned out it works great for this sort of problem. Possibly because it encodes the information about the objects in the middle layers, and then it just uses this knowledge to color the images properly, as image colorisation can also be considered a form of segmentation.
The dataset was procured from the safebooru image board, around 40,000 color images of manga drawings resized to 256x256. Then the black and white images would be generated from the color images and fed into the model:
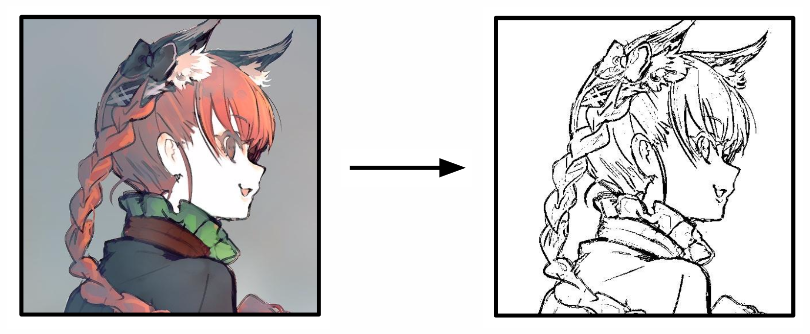
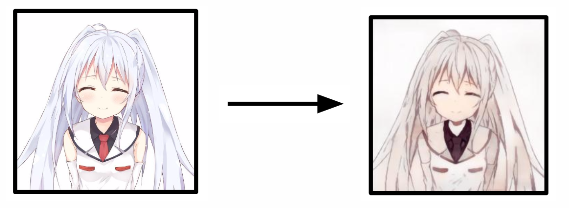
But unfortunately without any knowledge of the color, the model generated very grayish and bland images:
So as seen in this paper we added color hints to our model and this was the result:

We were pleased with the result since it was created in only 3 days. And we trained it on different models and configurations for only three nights on a couple of GTX1060. Also there were many failures that can be seen in our presentation here
Improvements
There are many possible ways to improve this result, one of them could be to use a different loss function and a different color space like in Colorful Image Colorization. Or maybe just train the network on a lot more samples with a harder hint. For now, I will leave it at that but maybe in the future, I could return to this little project and improve it.
References
Many people were doing similar things here, here, here and here. The last one is very similar to ours, the only difference is that we didn’t use a GAN.
Questions? Comments? Please ask them below.